こんにちは。
本日は以下のような社内データを活用したChatGPTサービスについての記事になります。
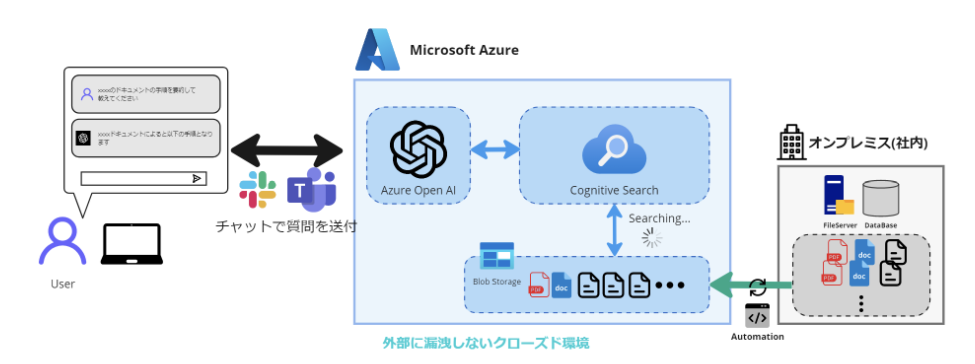
上記は企業の社内にあるファイルサーバーなどのデータを学習させる構成図になっていますが、今回はSharePointOnlineにあるドキュメントを学習させるため、Azure AI Search(旧:Azure Cognitive Search)でドキュメントのインデックス作成を行い、その後Azure OpenAIを活用してこれらの情報をChatGPTに学習させる方法について説明します。このプロセスを通じて、大量の社内文書から重要な情報を素早く抽出し、効率的に利用することが可能となります。
ただ、結構ボリューミーなので本記事に掲載する手順は、SharePoint Online上のデータをAzure Cognitive Searchにてインデックス化する手順までを掲載します。
[toc]
本記事に登場する製品の簡単解説
Azure AI Search(旧:Azure Cognitive Search)とは
Azure AI Search(旧:Azure Cognitive Search)は、Microsoft Azureが提供する全文検索とAIを統合した検索サービスです。様々なデータ源から情報を抽出し、ユーザーが必要とする情報を迅速に提供することができます。
Azure AI Search(旧:Azure Cognitive Search)とAzure Open AIとの連携
Azure AI Search(旧:Azure Cognitive Search)を利用することで、SharePoint Online上のドキュメントを全文検索可能な形式にインデックス化します。
そして、Azure OpenAIを用いて、このインデックス化された情報を学習させることで、効率的な情報抽出と活用を実現し、
社内の膨大な情報であっても適切なデータをすぐに取り出すことができます。
Azure AI Search(旧:Azure Cognitive Search)に登場する用語解説
レプリカ
検索サービスのインスタンスでクラスター内のノードに該当します。数を増やすことで進行中のインデックス作成操作を管理しながら、複数の同時クエリ要求を処理するためのバッファを確保することができます。
パーティション
インデックスを複数のストレージの場所に分割するために使用します。インデックスのクエリや再構築などのI/O操作を分割することが可能となります。
データソース
検索対象とするデータが格納されている場所を指します。Azure Cognitive Searchでは、これらのデータソースから情報を取得し、それを用いて検索可能なインデックスを作成します。これにより、手元にあるデータを効率的に検索し、活用することが可能となります。
スキルセット
データをより詳細に分析してより、リッチな情報を提供するための機能です。通常の製品であれば取得したデータのインデックスのみを作成しますが、Azure Cognitive Searchでは、AI技術を利用してデータの内容をより詳細に把握し、結果をインデックスに追加することで高度な検索を可能にしています。
Indexer(インデクサー)
インデックス作成プロセス全体を管理し、駆動するいわばエンジンになります。スキルセットのスキルを使用して抽出されたデータと元のデータソースから抽出されたデータおよびメタデータ値を取得し、洗練されたデータをインデックスのフィールドにマップします。
Index(インデックス)
必要とする情報を効率的に検索するための構造を持つデータセットのことを指します。インデックス作成プロセスを経て検索可能な形に整理された結果であり、具体的にはJSONドキュメントのコレクションで構成されます。
また、インデックスに対してクエリを実行することで、情報の取得やフィルター処理、並べ替えなども効率的に行うことが可能となります。
実際に設定してみる
Azure AI Search(旧:Azure Cognitive Search)の設定
それでは、早速試してみたいと思います。
今回はタイトルの通りSharePoint Online上のドキュメントをデータソースとして検索可能な状態にすることを目標としています。
Azure AI Search(旧:Azure Cognitive Search)の設定は基本的にUIでできる部分も多いですが、現在(2023年8月時点)、SharePoint Onlineはパブリックプレビュー段階であり、WebAPIを叩くことでしかデータソースからインデックスまでを生成できないようです。

実際にUIにも表示はされていません。いつかはUIでできるようになるとは思いますが。
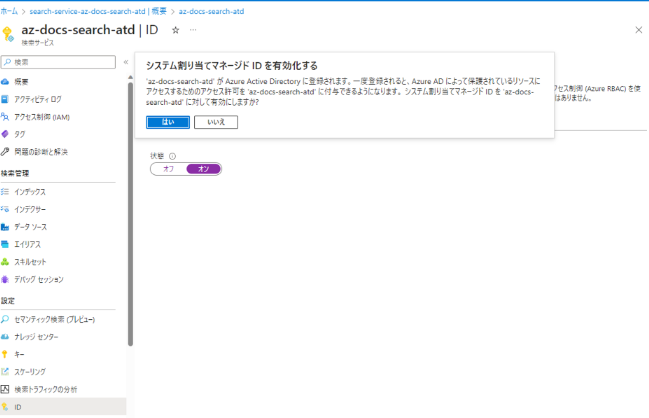
システム割り当てマネージドIDの有効化
インデクサーがSharePoint Onlineを検索するために必要となります。本手順はSharePoint OnlineサイトがCognitiveSearchと同一テナントの場合に必要となります。同一テナントでない場合はスキップで問題ないようです。
Cognitive Searchの[ID]メニューより、システム割り当てマネージドIDを有効にします。
インデクサーに必要なアクセス許可について
SharePointOnlineインデクサー( Cognitive SearchがSharePoint Onlineサイトに接続し、ドキュメント ライブラリにあるドキュメントのインデックスを作成する機能)は委任されたアクセス許可とアプリケーションアクセス許可の両者ともにサポートされているようです。
SharePointOnlineへアクセスはユーザーに代わってアプリが接続することになります。アプリがデータにアクセスするためには、権限や認証が必要です。
以下、委任されたアクセス許可とアプリケーションアクセス許可について解説されている記事となります。

なお、アプリケーションアクセス許可の場合は、クライアントシークレットが必要になります。
実は私は委任されたアクセス許可で試してみたのですがどうにもうまくいかず、アプリケーションアクセス許可にて対応を行いました。
追々調査はしていきたいと思いますが、以下Learnに記載の通り、該当テナントは条件付きアクセスを導入していることもあってうまくいっていない可能性があり、調査が難航しそうです。。
ですので本記事でもアプリケーションアクセス許可による手順を記載したいと思います。

AzureADアプリケーションを作成する
インデクサーがSharePoint Onlineにアクセスするためのアプリを作成します。上述で述べたように今回はアプリケーションアクセス許可を採用します。
本画面は特に操作は不要で[登録]をクリックして作成しましょう。
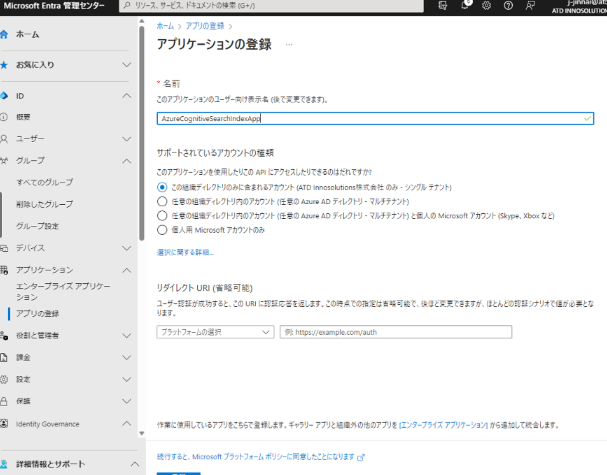
作成後、[認証]メニューより、[プラットフォームの追加]をクリックして[モバイル アプリケーションとデスクトップ アプリケーション]を選択します。
また、[パブリッククライアントフローを許可する]を有効にします。
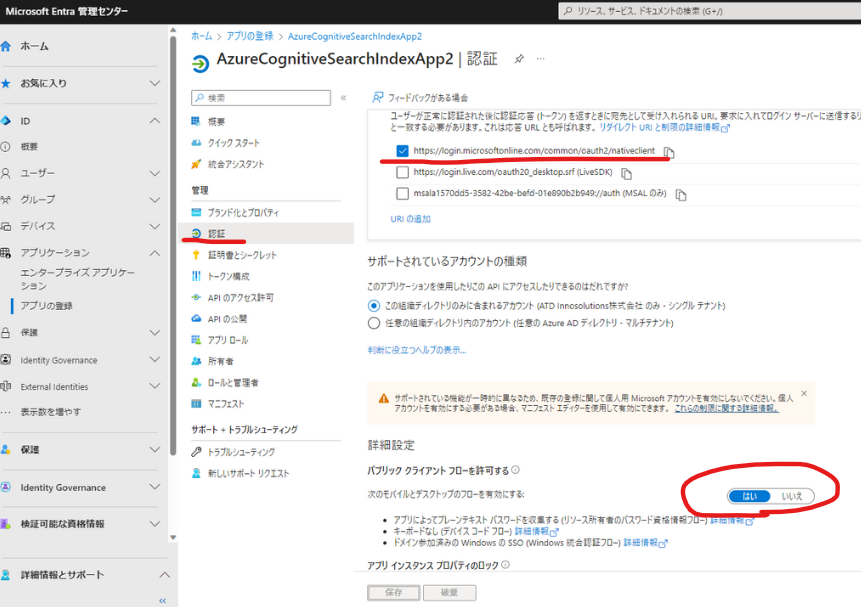
続いて、APIのアクセス許可を設定します。
[APIのアクセス許可]-[アプリケーションのアクセス許可]を選択し、以下を追加します。追加後は管理者の同意を与えます。
- Application – Files.Read.All
- Application – Sites.Read.All
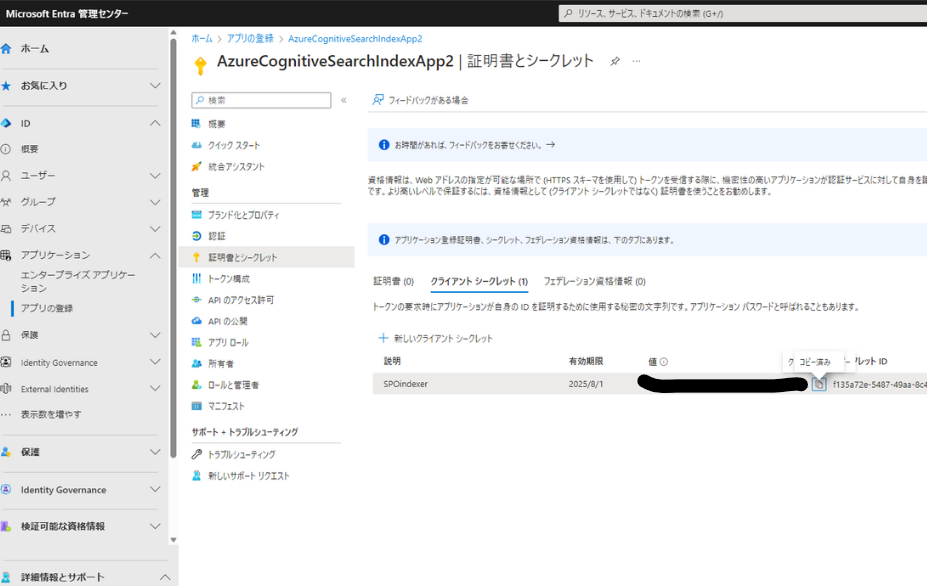
最後に、クライアントシークレットを作成して完了です。クライアントシークレットの値については後程使うのでメモしておきます。
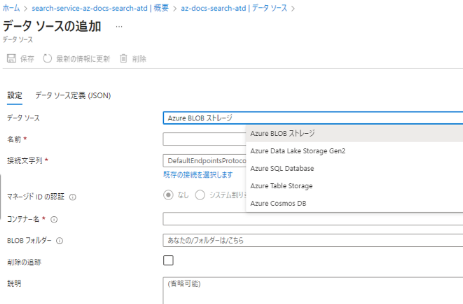
データソースの作成
さて、ここからが本題です。インデックス作成に伴い、データソースの作成からすべてWebAPIを叩く必要があります。
Learnでは、postmanなどChromiumのブラウザで拡張機能を追加して対応する手順が記載されていますが、ここではMicrosoft Edge標準搭載の機能を使って試していきたいと思います。
使い方については、以下の記事をご参照ください。

データソースの作成には以下を要求する形で対応します。
[]部分はご自身の環境に応じた値を入れてください。
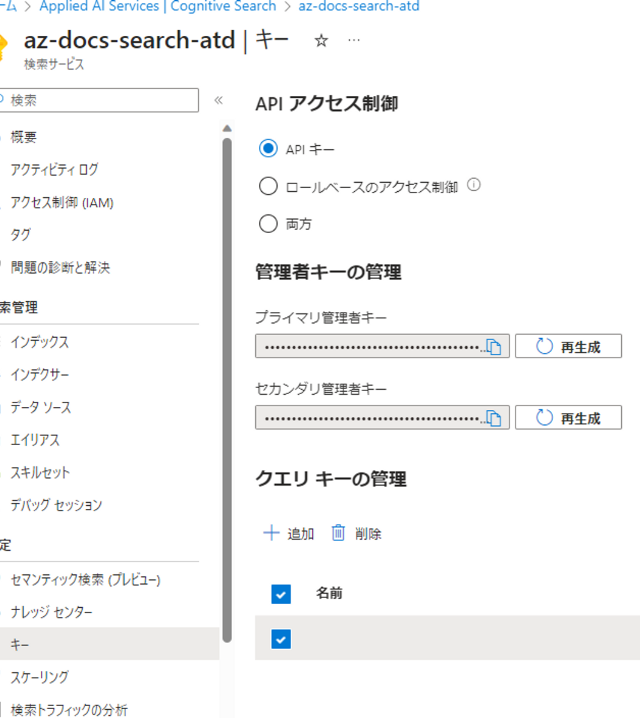
なお、API管理キーは以下CognitiveSearchの[キー]メニューより、プライマリ管理者キーから取得できます。
POST https://[CognitiveSearchのサービス名].search.windows.net/datasources?api-version=2020-06-30-Preview
Content-Type: application/json
api-key: [API管理キー]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "SharePointOnlineEndpoint=https://[SharePoint OnlineのサイトURL];ApplicationId=[上述の手順で作成したアプリケーションのアプリID];ApplicationSecret=[クライアントシークレットキー]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}うまくいけば、以下のように結果が返ってきます。
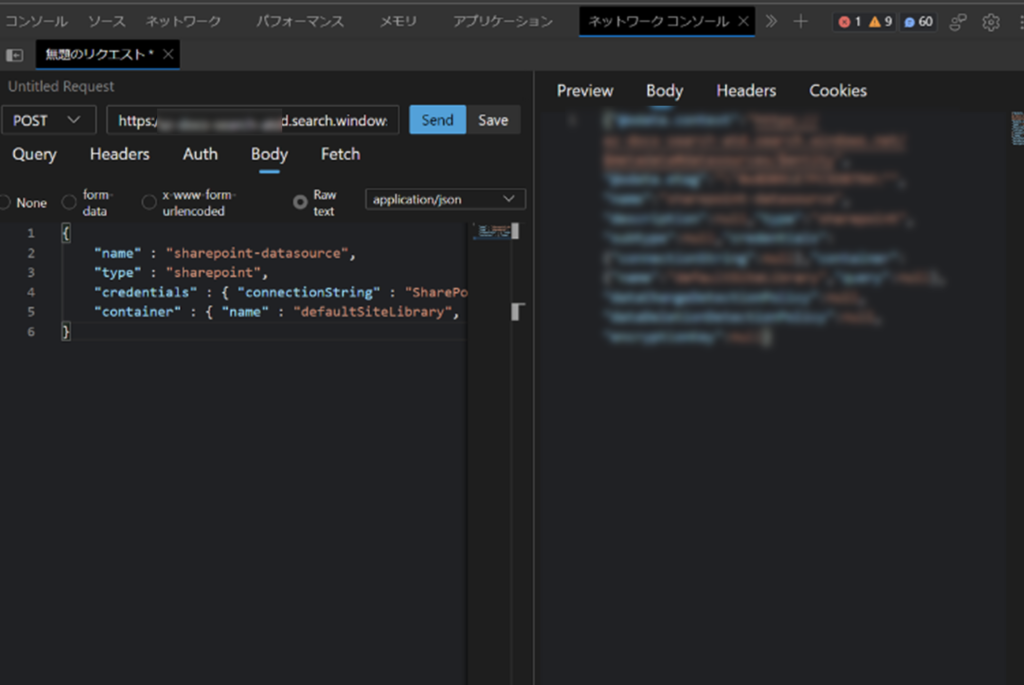
すると、データソースがすぐに生成されます。
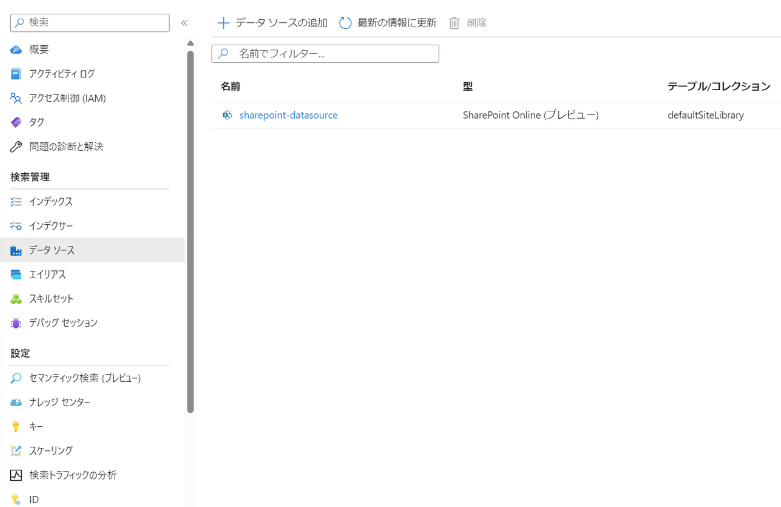
インデックスの作成
続いては、インデックスの作成です。
インデックスの作成もデータソースと同様にSharePointonlineにおいては現時点、WebAPIを要求して作成を行うしかありません。
また、ここで初めて登場するのがメタデータです。
イメージとしてはそのデータを説明するための情報で検索エンジンが整理し、特定の情報を効率よくに見つけられるようにする役割を果たします。そしてその情報に対してクエリを実行した際、メタデータは高度なフィルタリングやソートの操作を可能にし、特定の情報を即座に引き出す手助けをします。
インデックスの作成には以下を要求する形で対応します。
[]部分はご自身の環境に応じた値を入れてください。
POST https://[CognitiveSearchのサービス名].search.windows.net/indexes?api-version=2020-06-30
Content-Type: application/json
api-key: [API管理キー]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}インデックスが生成されていることがわかります。
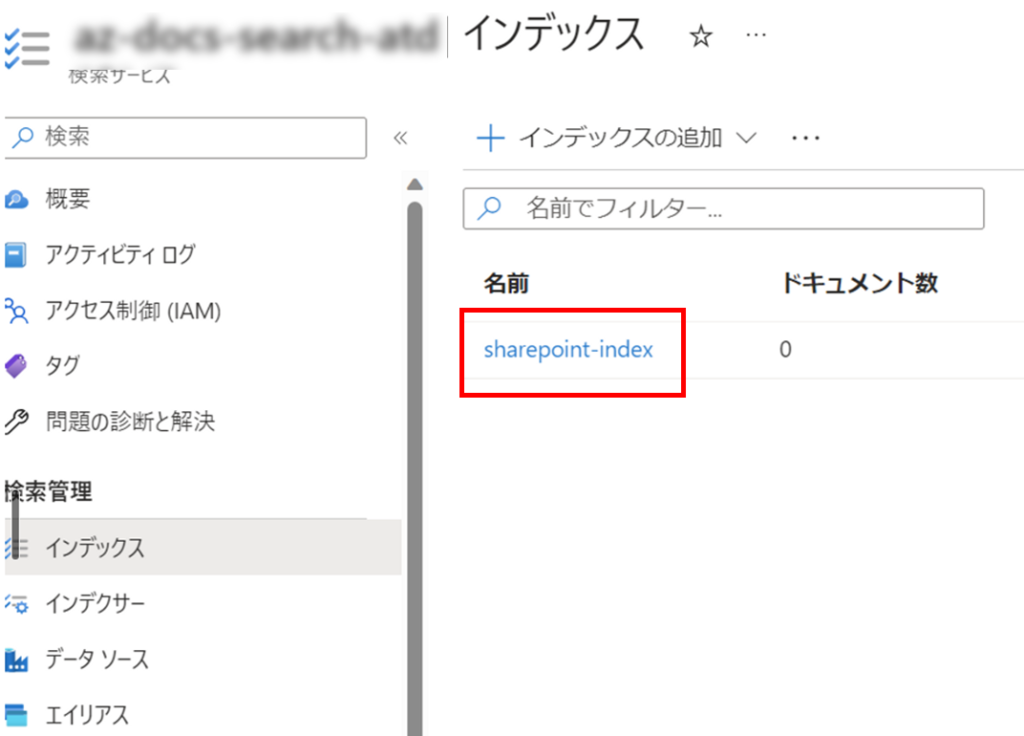
インデクサーの作成
最後はインデクサーの作成です。
インデクサーでは何を対象に検索を行うのかを定義します。
以下コードは検索対象の拡張子やスケジュール(24時間に1回で)を勝手にカスタマイズしております。ご参考まで。
では実際に実行してみましょう。
POST https://[CognitiveSearchのサービス名].search.windows.net/indexers?api-version=2020-06-30-Preview
Content-Type: application/json
api-key: [API管理キー]
{
"name" : "sharepoint-indexer",
"dataSourceName" : "sharepoint-datasource",
"targetIndexName" : "sharepoint-index",
"parameters": {
"batchSize": null,
"maxFailedItems": null,
"maxFailedItemsPerBatch": null,
"base64EncodeKeys": null,
"configuration": {
"indexedFileNameExtensions" : ".CSV, .EML, .JSON, .KML, .DOCX, .DOC, .DOCM, .XLSX, .XLS, .XLSM, .PPTX, .PPT, .PPTM, .MSG, .XML, .ODT, .ODS, .ODP, .PDF, .TXT, .XML, .ZIP",
"excludedFileNameExtensions" : ".png, .jpg, .EPUB, .GZ, .HTML, .RTF",
"dataToExtract": "contentAndMetadata"
}
},
"schedule" : {"interval" : "PT24H" },
"fieldMappings" : [
{
"sourceFieldName" : "metadata_spo_site_library_item_id",
"targetFieldName" : "id",
"mappingFunction" : {
"name" : "base64Encode"
}
}
]
}無事成功すると、以下のようにインデクサーが生成されていることがわかります。
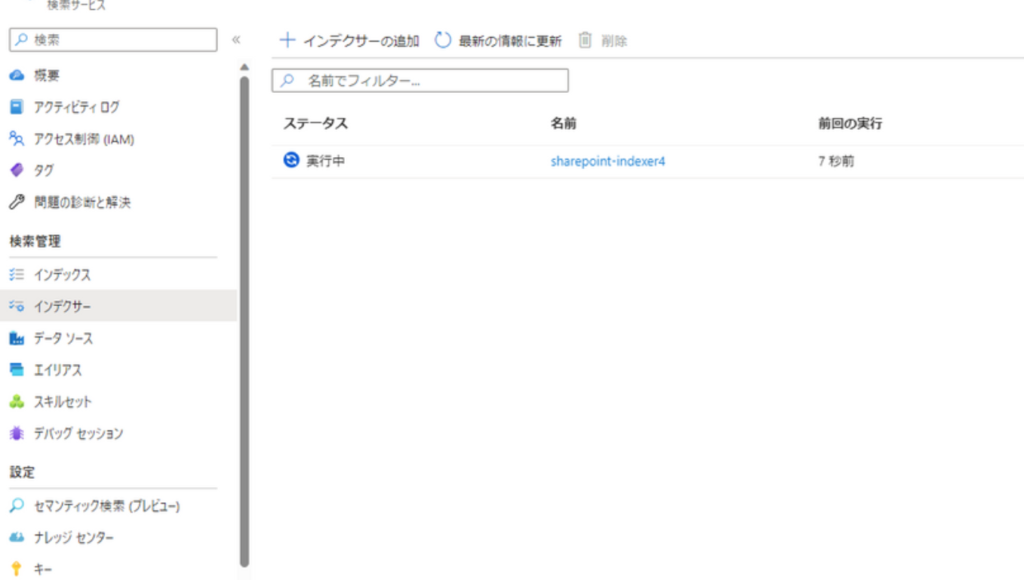
ちなみに後日確認してみたところ、ちゃんと1日1回実行されていることを確認できました。

まとめ
いかがでしたでしょうか?
Azure Cognitive SearchとAzure OpenAIを連携させて社内文書の学習を行うための準備作業として、AIがデータを読み込むための検索インデックスを生成する手順を解説いたしました。
今回はSharePoint Onlineをデータソースとして実施しましたが、これが社内のファイルサーバーなどに活用するとたとえば、過去の報告書や設計書にある有用な情報を短時間で抽出することができ、作業時間の短縮につながるはずです。
また、世の中のデジタル化が進んでいることもあり、社内で生成される情報は日々増え続けています。ましてや紙での管理なんてものは今後、なくなっていくことは必然であり、今後もこのようなAIとクラウドサービスの連携による情報管理の効率化が進むと予想されます。
弊社では、AIとクラウドサービスを活用して世の中の企業が役立つサービスの開発を行っております。
ご興味がありましたら是非、お問い合わせくださいませ。
また、弊社ではエンジニアを絶賛募集中です!
AI、IoT、Microsoft技術の道を進みたい人は是非連絡ください。

次回、元気があればAzure OpenAIとの連携についてを記事にできればと思います。お楽しみに!